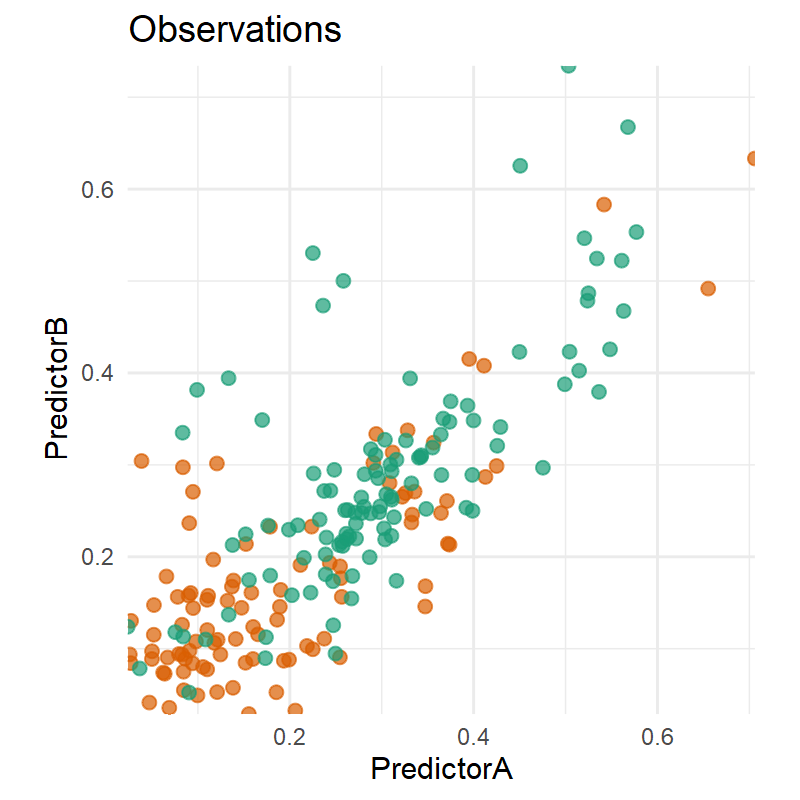
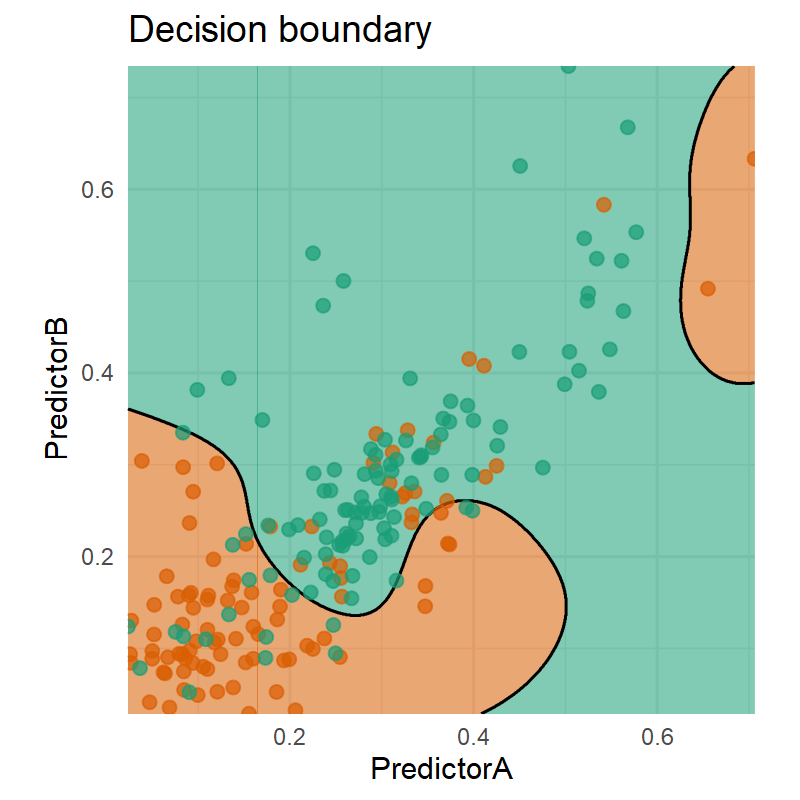
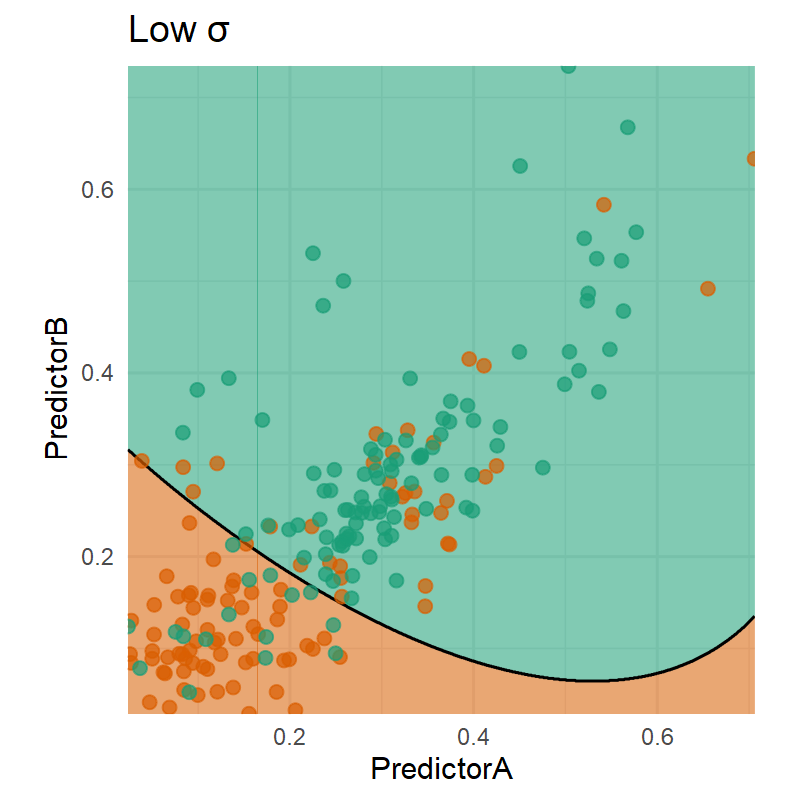
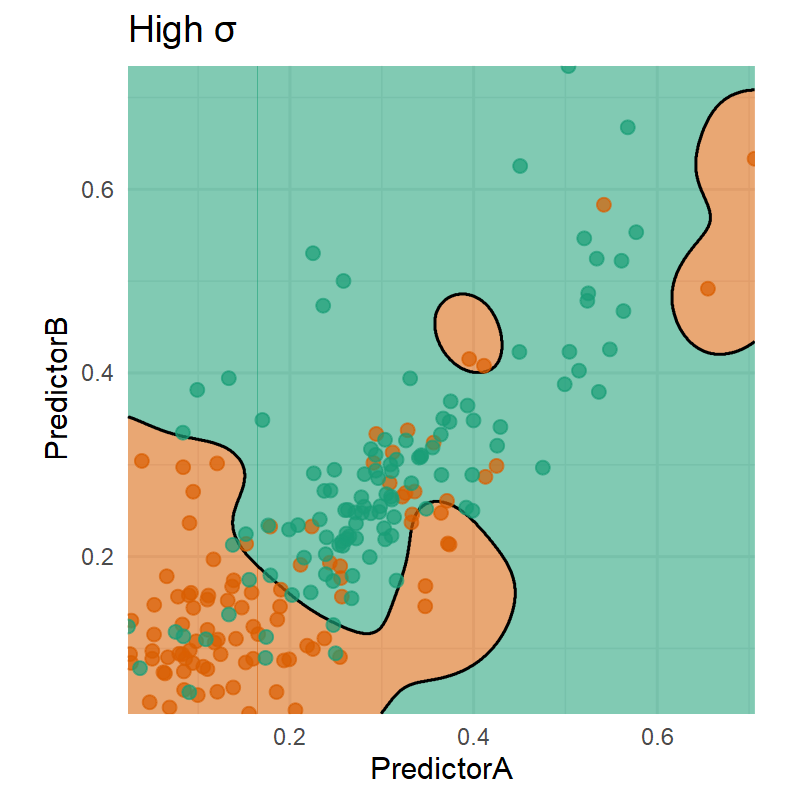
Code
set.seed(7)
imdb <- read_parquet("data/imdb.parquet")
imdb <- sample_n(imdb, 2000)
imdb |>
filter(nchar(review) < 800 & nchar(review) > 200) |>
filter(row_number() < 6) |>
kbl() |>
kable_styling(
html_font = "Century Gothic",
font_size = 14
)| review | sentiment |
|---|---|
| this show is the best it is full of laughs and Kevin James is the best so if you want a good show i recommend the king of queens and its a letdown that they canceled it so in the end this show will make you forget your worries and troubles cause if you have a cast with Kevin James and jerry stiller you cant go wrong. so i don't know why the canceled the show if any one knows please tell me.now a days you cant find a lot of shows that fulfill your needs as an audience.after Seinfeld and king of queens the only show worth watching is prison break and if that stops i don't know what to do. in the end if i had to recommend a show it will be king of queens. | positive |
| "Undercurrent" features a top-notch cast of wonderful actors who might've been assembled for the perfect drawing-room comedy. Alas, they are pretty much wasted on a 'woman's view' potboiler--and a paper-thin one at that. Katharine Hepburn is indeed radiant as a tomboy/old maid who finally marries, but her husband is deeply disturbed and harboring dark family secrets. Director Vincente Minnelli has absolutely no idea how to mount this outlandish plot, concocted by Edward Chodorov from a story by Thelma Strabel, and the friendly, first-rate cast (including Robert Taylor, Robert Mitchum and Edmund Gwenn) is left treading in murky waters. ** from **** | negative |
| For those out there that like to think of themselves as reasonably intelligent human beings, who love film, have good attention to detail and enjoy indie movies with funny, smartly written dialogue then this is a film for you.<br /><br />For those with a poor attention span, high expectations and no brains.. well.. um.. you may get bored and find things dragging at times.<br /><br />This is a charming, modest and well paced movie with the actors bestowing a real sense of depth and warmth to their roles. I chuckled to myself pretty much the whole way through..<br /><br />This film is a little gem. | positive |
| I am surprised than many viewers hold more respect for the sequel to this brilliant movie... I have seen all the guinea pigs and this one is easily the best.<br /><br />Even though ive seen the "making of", i still have doubts when watching those 35mins of pure torture : its that powerful.<br /><br />A 10 out of 10 because this movie achieved perfectly what it set out to do : be the best fake snuff film ever made. | positive |
| The whole movie was done half-assed. It could have been a much better movie but, that would have required a re-write and different actors. Compared to "Traffic" this was a wreck. I am just glad I didn't have to pay for it.<br /><br />Spoiler:<br /><br />What was the point of having crooked cops getting arrested? To share the guilt of drug dealers and make them feel better? Pu-leaze! The parents were scum, driven by greed, and didn't even consider the harm they were doing; as pointed out by Ice-T. <br /><br />2 out of 10 | negative |